
JavaScript, bots y ChatGPT: lo que realmente ocurre cuando el contenido “no es accesible”
En los últimos meses, en el mundo del SEO y el GEO ha surgido una pregunta cada vez más habitual: ¿cómo puede ChatGPT responder correctamente a preguntas cuya información parece existir únicamente en páginas renderizadas por JavaScript?
La duda es razonable. En teoría, ChatGPT no renderiza JavaScript como un navegador: no ejecuta código, no espera llamadas asíncronas ni accede al DOM final tras el renderizado. Y aun así, las respuestas están ahí.
Este artículo no parte de una hipótesis, sino de un caso real. Surge tras analizar logs de servidor, user agents y arquitecturas SPA en producción para uno de nuestros clientes, y después de poner a prueba directamente a ChatGPT con preguntas muy concretas
No es un caso teórico. Es un caso práctico.
Tabla de contenidos
El contexto: un sitio 100 % dependiente de JavaScript
El sitio web de uno de nuestros clientes funciona como una Single Page Application (SPA). El HTML inicial que devuelve el servidor contiene únicamente:
- Un <div id=»root»></div> vacío
- Cargas de bundles JavaScript
- Un mensaje explícito en <noscript> indicando que sin JavaScript el sitio no funciona
Y no existe actualmente:
- Renderizado del lado del servidor (SSR)
- Prerender funcional
- Caché HTML con contenido renderizado
Dicho de otro modo: si no se ejecuta JavaScript, el contenido no existe. Y aun así, ChatGPT:
- Respondía correctamente a preguntas muy específicas
- Citaba exactamente la página concreta del centro de ayuda
- Coincidía palabra por palabra con el contenido visible solo tras la ejecución de JS
El detonante: los logs del servidor
Al analizar los archivos de log, detectamos un aspecto clave:
Cada vez que se realizaba una pregunta en ChatGPT relacionada con ese contenido, aparecía una petición casi simultánea desde el user agent: ChatGPT-User/1.0
La conclusión inicial parecía obvia: ChatGPT debe estar ejecutando JavaScript. Pero al contrastar esto con el HTML real servido a ese user agent, la hipótesis empezaba a romperse.
El reto directo a ChatGPT
Planteé la contradicción de forma explícita:
- Si el user agent ChatGPT-User no ejecuta JavaScript
- Si el HTML servido no contiene el contenido
- Si no existe SSR ni prerender activo
¿Cómo es posible que ChatGPT conozca el contenido exacto de esas páginas?
Aquí es donde la conversación dejó de ser superficial y entró en terreno realmente interesante.
El error común: asumir que el User-Agent define el renderizado
Uno de los grandes aprendizajes de este proceso es entender que el User-Agent que aparece en los logs no define el pipeline completo de acceso al contenido.
Es un error muy común (y comprensible) asumir esta cadena:
User question → HTTP request → HTML response → lectura del contenido
Pero en sistemas modernos de recuperación de información (como los que utiliza ChatGPT), esta cadena no es lineal ni directa.
Cómo funciona realmente el acceso al contenido (modelo mental correcto)
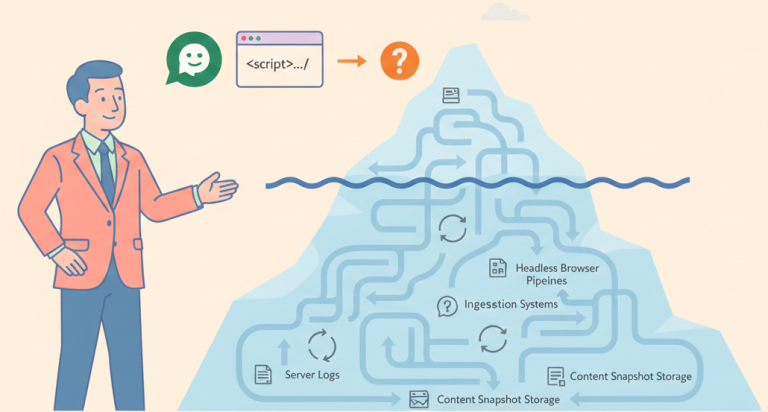
Aquí es donde conviene introducir el primer diagrama visual:

El proceso real se parece mucho más a esto:
- El usuario lanza una pregunta
- El sistema decide si ya existe contenido relevante almacenado
- Se evalúa si es necesario validar una URL o comprobar disponibilidad
- Se ensambla la respuesta a partir de múltiples fuentes posibles
La petición con el user agent ChatGPT-User suele pertenecer al paso de validación o anclaje, no necesariamente al de adquisición del contenido.
Entonces, ¿cómo accede ChatGPT a contenido renderizado por JavaScript?
Aquí es donde entra la parte menos conocida, y menos documentada, del ecosistema.
Renderizado fuera de banda (out-of-band rendering)
ChatGPT sí dispone de pipelines internos capaces de ejecutar JavaScript, equivalentes a navegadores headless. Pero estos pipelines:
- No están documentados públicamente
- No tienen user agents estables
- No se activan en todas las peticiones
- No son detectables desde los logs del sitio web
- No constituyen una garantía para publishers
El renderizado puede haber ocurrido:
- Días o semanas antes
- En otro sistema interno
- Como parte de un proceso de ingestión previo
Una vez renderizado y extraído el contenido, este puede almacenarse como snapshot y reutilizarse.
La importancia del tiempo: ingestión desacoplada
El orden real puede ser perfectamente este:
- T-30 días: el contenido se renderiza e ingiere
- T-7 días: se refresca un snapshot
- T-ahora: el usuario hace la pregunta
- T-ahora: ChatGPT-User accede a la URL para validarla
- T-ahora: la respuesta se genera a partir del contenido ya conocido
Esto explica por qué:
- El contenido es exacto
- La página citada es correcta
- El HTML servido en ese momento no contiene nada útil

Por qué esto es intencionadamente opaco
¿Por qué no se documenta todo esto de forma clara? La respuesta es estratégica y técnica a la vez.
Si ChatGPT garantizara públicamente:
- Ejecución de JavaScript
- Paridad con navegadores reales
- Comportamientos deterministas
Se abriría la puerta a:
- Cloaking
- Manipulación por user agent
- Dependencias técnicas frágiles
- Expectativas contractuales imposibles de mantener
Por eso, el acceso a contenido JS-renderizado es opaco, no contractual y no señalizado por User-Agent.
La conclusión clave para SEO y GEO
Que algo funcione hoy no significa que sea fiable. En nuestro caso:
- ChatGPT accede al contenido
- Responde correctamente
- Pero lo hace a través de mecanismos que no controlamos ni podemos garantizar
Desde una perspectiva SEO y GEO, esto nos lleva a una conclusión clara: si el contenido no existe en el HTML inicial, su accesibilidad para sistemas de IA es circunstancial, no estructural.
Este ejercicio no fue una discusión teórica, sino un diálogo técnico basado en pruebas reales, logs y comportamiento observable. Retar a ChatGPT con datos concretos permitió ir más allá de respuestas genéricas y entender cómo funcionan realmente los sistemas modernos de recuperación de información.
Y, sobre todo, deja una lección importante para cualquier estrategia digital actual: no optimizamos solo para buscadores sino para sistemas de comprensión… Y la comprensión necesita contenido accesible, no solo interfaces bonitas.